

Deployment Frequency as a Business Metric
How to explain to the CFO that "shipping code 5 times a day" is about reducing the feedback loop between a business request and a delivered insight.

It is 4:00 PM on a Friday. A senior engineer has a finished pull request that fixes a nagging reporting bug. The logic is sound, the tests pass locally, and the business has been asking for this fix for three days. But they don’t hit merge.
Instead, they close their laptop. They know that if they deploy now and something breaks, they are looking at a ten-hour weekend marathon of manual rollbacks and forensic data cleaning. In this environment, “No Deploy Friday“ is a survival strategy.
Leadership looks at this and sees a team being “careful“. They think waiting for a scheduled monthly release window is a form of quality control.
They are wrong.
They are actually witnessing the accumulation of “deployment debt“, a massive batch of unverified changes that will eventually explode in a “Big Bang“ release.
Deployment frequency is a business metric that defines the feedback loop between a business request and a delivered insight. If you want to move faster and break less, you need a process where quality is a structural requirement.
The Price of the Big Bang Release
Large batch releases create a false sense of security. Bundling thirty different changes into one window creates a complex system where components interact in unpredictable ways.
Finding the root cause of a failure in a four-week deployment cycle requires a forensic investigation. I spend days unpicking dependencies while you wait for the dashboard to come back online.
A proper CI/CD pipeline acts as a structural safety net. It forces every line of code through automated gates before it reaches production. These gates include unit tests for logic, integration tests for data flows, and staging environments that mirror reality.
If a check fails, the process stops. This constraint ensures only verified, reversible changes enter the system.
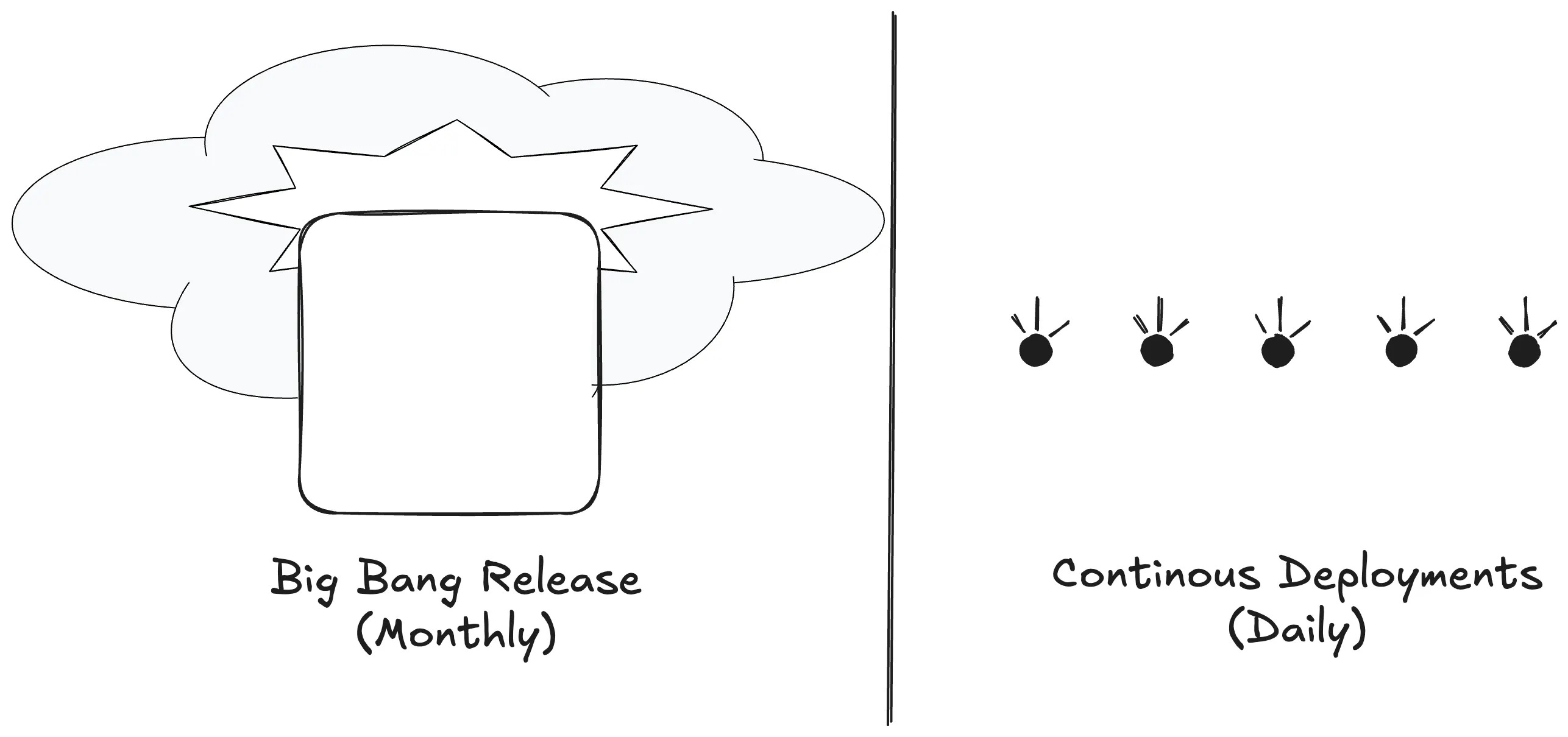
Fixing a minor bug in a two-hour-old update is inexpensive. The context is fresh and the impact stays contained to a single change.
Fixing a systemic failure in a monthly release costs ten times more in lost productivity and downtime. Frequent deployments lower the stakes of being wrong. You trade a “Big Bang” catastrophe for a manageable, immediate fix.
Shifting to a daily rhythm requires a change in how we view technical labor. Use the following framework to reframe deployment costs for your leadership.
