

Data Engineers Are Becoming MetadataOps Engineers (And You Don't Even Know It Yet)
The paradigm shift from serving dashboards to powering AI systems: same foundation, new layer on top.

Hi fellow data nerds,
Today, I have a special guest post by Alejandro Aboy. If you are interested in Data Engineering, AI and the intersection between thest two, definitely subscribe to Alejandro’s newsletter.
Enjoy!
TL;DR
Your data pipelines work, but AI agents can’t use them. The consumer changed from analysts to LLMs, and “quality” now means semantic context, not just correct types.
Documentation is a prompt. Every table description and API field becomes input for LLM reasoning. Vague metadata = hallucinations.
Traditional quality tests (not null, unique, referential integrity) don’t cover AI readiness. Add “Can an AI understand this?” to your definition of done.
Governance, RAG pipelines, and monitoring all need the same upgrade: metadata as APIs, AI-specific lineage, and agent behavior tracking.
Data Engineers who get MetadataOps own AI product features, get hired for high-visibility roles, and build skills that can’t be automated.
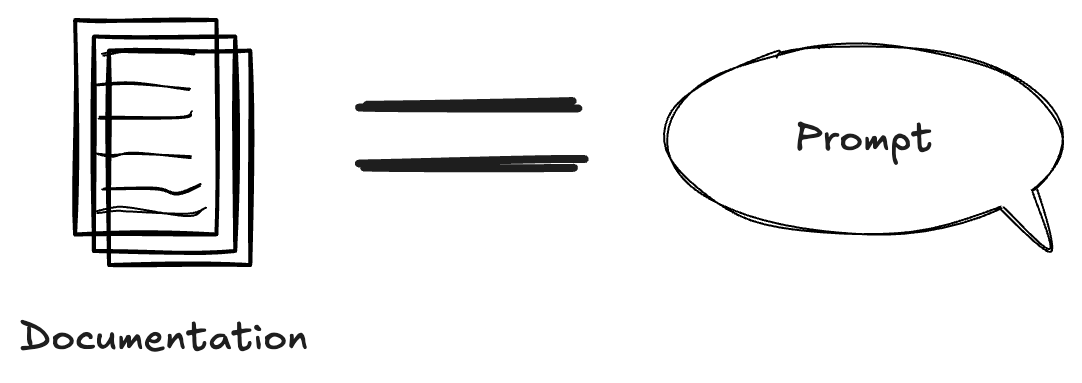
You just spent the last three months building a flawless dbt pipeline. Tests pass. Data is fresh. Dashboards load quickly.
Then someone ships an AI agent that’s supposed to answer business questions.
Within hours, it’s hallucinating revenue numbers. It’s retrieving the wrong tables. It’s inventing documentation links that don’t exist. Users are confused. Leadership is asking questions.
And you realize: Your infrastructure succeeded, but your AI failed.
You and I both know what’s happening. The industry sold you on “data-driven decision making” through BI tools.
You learned SQL, dbt, Airflow, data modeling.
You built pipelines that move data from A to B reliably.
Now the consumer changed. And they don’t browse catalogs or write SQL queries. They search semantically. They reason over metadata. They fail silently (or confidently hallucinate right answers) when context is missing.
AI will act as a confused junior during onboarding if you don’t understand that what “quality” means just shifted underneath you.
The (New) Data Stakeholders
Let’s be direct about what’s at stake.

Before Now Consumer Analysts AI agents, LLMs Interface SQL, BI dashboards Semantic layers, embeddings, MCP servers Success Metric “Does the dashboard load?” “Does the AI give accurate answers?” Quality Definition Correct types, no nulls, referential integrity Complete context, semantic structure, AI readiness
The definition of success is no longer limited to dbt running without errors. Now you’re also responsible for metadata quality.
When it comes to career implications:
Data Engineers who get MetadataOps:
Own AI product features (not just “the plumbing”)
Get hired for AI projects (higher comp, higher visibility)
Build skills that can’t be automated (AI needs humans to generate context)
Stop believing that their role is “move data from A to B”
The Five Shifts Nobody Prepared You For
Shift 1: Documentation Is A Prompt
The old game: You wrote descriptions so humans could find tables in a data catalog. You kept it short because nobody reads documentation anyway. Data Governance & Semantics were optional for most of the companies.
Table: fact_orders
Description: Orders table
Columns: order_id, customer_id, total, created_atAnalysts saw “fact_orders” and knew to look there for revenue.
The new game: An AI agent tries to answer “What’s our Q4 revenue by region?” and it retrieves stg_stripe_payments_raw instead of fact_orders. It includes refunds in the calculation because nothing in your metadata says not to.
If before was quite a challenge to build trust, imagine what would happen when Leadership makes a decision based on hallucinated data because “it sounded so convincing“.
An example on how this could look: (example with cube.dev)
cubes:
- name: orders
sql_table: fact_orders
description: >
Completed purchase transactions. One row per order.
Excludes refunds, test orders, and cancellations.
Use for revenue analysis and order trends.
Fallback options:
- For item-level detail → query 'order_items' cube
- For payment/refund tracking → query 'payment_transactions' cube
- For real-time data (<1hr) → query 'stg_orders_raw' table
measures:
- name: revenue
sql: total
type: sum
description: >
Total revenue in USD. Auto-excludes refunds, test data, and cancelled orders.
Note: This is NET revenue. For GROSS revenue (before refunds), use 'gross_revenue' measure.
filters:
- sql: "{CUBE}.status = 'completed' AND is_test = false"
meta:
currency: USD
common_queries:
- "Q4 revenue? → SUM(revenue) WHERE quarter = 4"
- "Revenue by region? → GROUP BY region"
troubleshooting:
- "Numbers don't match Stripe? Check 'payment_transactions' for reconciliation"
- "Missing recent orders? Check 'stg_orders_raw' (refreshes every 5min)"
joins:
- name: customers
sql: "{CUBE}.customer_id = {customers.id}"
relationship: many_to_one
meta:
refresh: hourly
quality: "99.8% complete, <1hr latency"The same principle applies to APIs. If you’re exposing data to AI agents, don’t assume they’ll understand ambiguous field names:
// ❌ Human-readable (AI guesses)
{"total": 23450, "status": "active", "type": 2}
// ✅ AI-readable (explicit context)
{
"total_revenue_usd": 23450,
"subscription_status": "active", // values: active, paused, cancelled
"subscription_type": "premium", // mapped from type_id=2
"metadata": {"currency": "USD", "includes_tax": false}
}The Shift: Every description you write becomes context for an LLM reasoning task and also becomes potential input for hallucinations if handled the wrong way.
If you’re still treating metadata as a “nice to have” that you fill out when you have time, you’re building pipelines that AI can’t consume.

Shift 2: Your Quality Tests Are Measuring the Wrong Thing
Let’s talk about what “quality” actually means now.
Your current quality framework:
✅ Revenue is never null
✅ Customer IDs match the customers table
✅ No duplicate order IDs
Then the AI agent fails:
❌ Can’t find the right table via semantic search
❌ Misinterprets “revenue” (is it gross or net?)
❌ Includes test data in production queries
You’re testing data quality. You’re not testing AI readiness.
AI readiness checks you should be running:
Do all columns have descriptions with examples and units?
Does metadata explain edge cases, exclusions, and business logic?
Are common query patterns documented with examples?
An analyst can see ambiguous metadata and ask clarifying questions. An AI agent just guesses confidently wrong.
The Shift: Add “Can an AI understand this?” to your definition of done. Your data can be 100% correct and 0% usable by AI. Become the owner who can make this work the right way.

Shift 3: Data Governance As A Pipeline
You built perfect governance: lineage tracking, metadata catalogs, impact analysis. Your auditors love it.
But your AI agents can’t access it.
The problem: Your lineage lives in a UI. Your metadata sits in a catalog humans search. Your quality metrics live in dashboards.
An agent asks: “If I change the orders table, what breaks?”
You have perfect lineage. But the agent can’t query it. It guesses. It’s wrong.
What you need:
Lineage as APIs - Expose graphs so agents can query “what depends on this table?”
Metadata as semantic search - Make catalogs searchable by embeddings, not keywords
Quality metrics as context - Feed scores into prompts: “This table is 95% complete, refreshed 2hrs ago”
The Shift: Your governance pipelines shouldn’t just populate catalogs for humans. They should generate semantic context AI agents need. End-to-end lineage isn’t just for auditing—it’s the foundation for agents to answer “what breaks if I change this?”

Shift 4: RAG Pipelines - The ETL of AI
Your RAG agent hallucinates a link. You can’t debug it because you have no idea which document was retrieved, what chunking strategy was used, or which embedding model generated the vectors.
You’re treating document ingestion like a black box: upload, chunk, embed, pray.
What breaks: When retrieval fails, you have zero visibility into source → chunk → embedding → retrieval → response.
Track source version, chunking strategy, embedding model, retrieval score, refresh cadence.
When AI fails, trace back: “Chunk 47, embedded 90 days ago with stale model, retrieved with 0.43 confidence.”
Now you can fix it.
The Shift: You wouldn’t run a transformation without lineage tracking. Don’t run document ingestion without metadata tracking.
Shift 5: Monitoring Pipelines ≠ AI Observability
SLAs, task executions times and job completions will still be relevant for the good old ETL.
But when it comes to AI systems, most of the monitoring is hiding lots of silent errors.
Logs on Grafana might look good, users don’t complain.
Then you check random conversations and the agent starts linking to documentation that doesn’t exist, always query the same table for the wrong thing, explaining API errors to users rather than having fallback logic in natural language.
The new monitoring implies asking other questions:
Which tables do AI agents actually query?
When do agents hallucinate vs. give accurate answers?
Which metadata descriptions lead to better responses?
Are there usage patterns we didn’t anticipate?
The Shift: Every AI interaction is user feedback about your AI Product. If you’re not monitoring agent behavior and acting on all the silent feedback it’s producing, it’s just another “dashboard that nobody looks at”

Start Evolving
You’re not leaving Data Engineering. You’re evolving it.
What Stays What’s Added dbt models + semantic layer configs ETL pipelines + metadata extraction Data quality tests + AI readiness checks Performance monitoring + agent behavior analysis How to actually make this shift:
Stop collecting certifications. Start building Proof of Work.
Pick one table. Rewrite its description so an AI agent can understand it: purpose, grain, common queries, edge cases. Then test it. Ask your favorite LLM questions that should hit that table and see if it gets it right. Iterate until it does.
That’s it. That’s the starting point.
Once you see how much metadata quality changes AI output, the rest follows naturally: semantic layers, observability tools, agent monitoring. You won’t need a roadmap because the problems will tell you where to go next.
Here’s what nobody tells you:
The companies winning with AI aren’t replacing Data Engineers.
They’re evolving them into MetadataOps Engineers.
Make the shift:
Own AI product features (not just pipelines)
Speak the language of product teams
Build skills that can’t be automated
Get hired for high-visibility roles
Classic data engineering built infrastructure for dashboards. MetadataOps engineering builds infrastructure for AI systems.
The paradigm is shifting. You can evolve with it or get left behind.
 | A guest post by
|
MetadataOps Engineer new job title?