

The Missing Map to AI-Powered Apps for Data Engineers
AI engineering looks new until you lay out the moving parts and realize it runs on state, latency, and data integrity like everything else you’ve shipped.

This article is part of the AI for Data Engineers playlist. Click here to explore the full series.
I have been building data systems long enough to know when something is actually new and when it is just renamed. Lately, I have been building AI-powered systems, and I am deeply invested in one I will share very soon. None of this work surprised me technically. What surprised me was how people talk about it.
I ran a Show & Tell with my team recently. Smart, senior data & analytics engineers. They all knew what an LLM was. They all had opinions about prompts. Yet as the discussion went on, it became clear they were treating AI apps as a foreign category, not as systems. Models were visible. Everything around them was blurry.
Data engineers already touch most of the moving parts inside an AI-powered app. They just lack a shared dictionary that maps AI terms back to the work they already do every day.
In this piece I lay out a map. Once the terms snap into place, AI engineering stops feeling like a leap and starts looking like adjacent work you already know how to reason about.
An AI App Is a Pipeline With a Probabilistic Output
An AI app is an ETL pipeline whether you call it that or not. Inputs move through a sequence of steps, intermediate state gets created, and outputs depend on everything that ran before them. The system has order, dependencies, and failure points.
A single LLM call behaves like a transform. It accepts an input payload, applies logic you do not fully control, and emits an output. Once you add retrieval, retries, tool calls, or memory, you are chaining transforms. At that point, reasoning in terms of prompts stops working. You reason in terms of flow.
This matters because variance enters at the end of the pipeline instead of the beginning. The structure stays intact. State still accumulates. Latency still compounds. Errors still propagate forward. You debug the system by isolating stages, not by rereading prompts.
Most AI confusion comes from treating the model as the system. In practice, the model is one step in a longer execution path. The quality of the app depends less on the cleverness of that step and more on how the steps around it constrain what reaches it and how its output gets used.
Once you see the pipeline, familiar instincts kick in. You start asking where state lives, which steps are allowed to fail, and what gets cached or retried. That shift is the entire point of this map.
RAG Is a Lookup Join With Better Marketing
RAG stands for Retrieval-Augmented Generation. In practice, it means the model answers a question using external data pulled in at request time.
The flow is straightforward. An input comes in. The system retrieves related documents from a separate store. That retrieved context gets attached to the request. The model produces an output using both the input and the added context.
Structurally, RAG is enrichment. You take an input record, look up related context from a side store, and attach that context before the final transform runs. The only unusual part is the lookup key. Instead of equality, you search by similarity.
Everything else follows familiar patterns. You ingest source data. You transform it into a retrievable shape. You index it. At runtime, you fetch a subset and join it into the request. If the wrong context comes back, the output degrades, just like any bad join poisons downstream results.
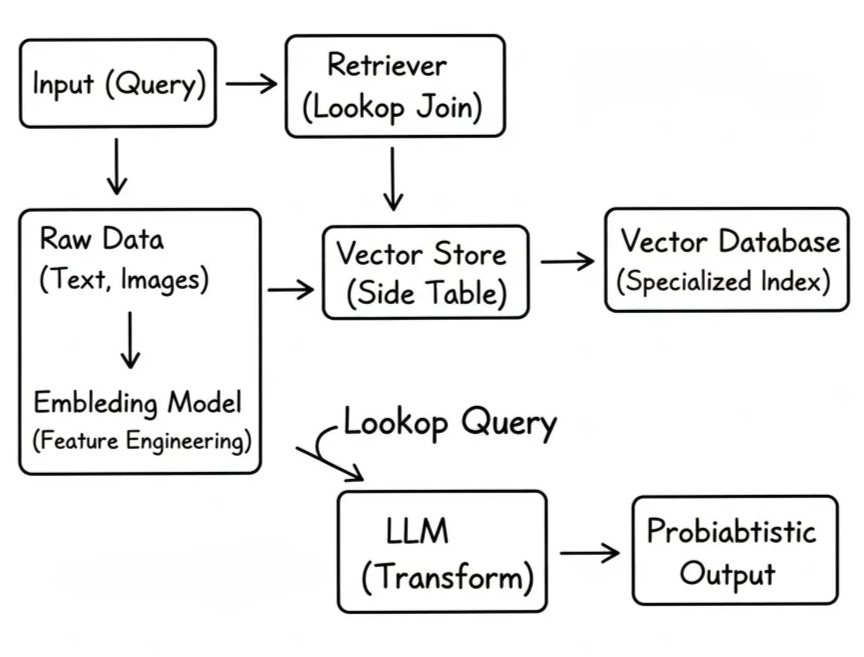
The hard problems in RAG have nothing to do with prompts. They live in freshness, coverage, and skew. Stale documents produce confident wrong answers. Biased retrieval produces consistent hallucinations. Overly broad retrieval bloats latency and cost.
Once you see RAG as a lookup join, your instincts shift. You start asking what table you are really joining against, how often it updates, and what guarantees exist around what comes back. That is the work. The model call is just the final transform.
Embeddings Are Feature Engineering for Unstructured Data
Most AI systems start with inputs that refuse to sit in tables. Text, images, logs, conversations. The first problem is not intelligence. It is representation.
An embedding is a transformation that turns unstructured input into a fixed-length numeric vector. The vector captures relationships between inputs in a way machines can compute on. Similar inputs land closer together. Dissimilar ones drift apart.
From a data engineering perspective, this is feature engineering. You take raw, messy input and serialize it into a shape downstream systems can index, compare, and retrieve. The output is lossy by design. Fidelity gets traded for computability.
Once you frame embeddings this way, the decisions become familiar. What inputs go in. When they get recomputed. How stable the representation stays over time. Drift here behaves like feature drift anywhere else. Retrieval quality degrades quietly until the system starts sounding wrong.
Embeddings do not add meaning. They enable lookup. They exist so unstructured data can participate in pipelines that expect structure. Everything built on top of them inherits that constraint.
Vector Databases Are Specialized Indexes
A vector database exists to support the most common access pattern in AI: similarity search over embedded data. That is the whole job, and everything else is packaging.
Once you generate embeddings, you need a way to store them and retrieve the closest matches quickly. A vector database provides an index optimized for distance. Instead of asking “does this value match”, you ask “what is close enough”.
From a data engineering perspective, this is an index choice. You trade strict correctness for speed and recall, so you gain approximate answers that arrive fast, but lose explainability and exact guarantees.
Vector databases work well when coverage matters more than precision. They struggle when results must be precise or auditable. The moment you need to explain why a record was returned, the abstraction starts leaking.
Treating vector databases as specialized indexes keeps the conversation grounded. You stop asking which tool is best and start asking which guarantees you are willing to relax. That framing matters far more than vendor selection.
Want to learn more about other database types? Check this peiece here:

Agents Are Tasks That Carry State
An agent is a task with memory. It takes input, runs some logic, writes or returns output, and hands state forward to whatever runs next.
If you have built Airflow DAGs, you already know the shape. A DAG is a set of tasks with explicit ordering, clear boundaries, and shared state passed through XCom, tables, object storage, queues, or APIs. Each task does one job, then hands off, and the system works because execution stays legible.
An “agentic” system keeps the same building blocks, then changes how the next step gets chosen. Instead of defining every edge ahead of time, the system often decides the next step at runtime based on model output. Generated text triggers actions like “retrieve more context”, “call an API”, “write a summary”, or “stop.”
Airflow gives you a static graph you can inspect before it runs. Agent runtimes assemble parts of the graph while they run. Retries become harder to reason about because the same input can take a different branch. Partial state persists across steps that never ran together in your original mental model. Debugging turns into reconstructing an execution path from traces instead of reading a DAG.
This is why the agent conversation matters to data engineers. The “intelligence” is mostly orchestration plus runtime branching. The real work stays pretty much the same: define boundaries, pick where state lives, decide what is replayable, and constrain the parts that can’t be trusted to behave deterministically.
Orchestrators Exist Because One Call Is Never Enough
The moment an AI app does more than one model call, orchestration becomes unavoidable. You need to decide what runs first, what runs next, and what happens when something fails halfway through.
This is familiar territory. If a single LLM call maps to a SQL query, then an AI app maps to a workflow. You chain calls together. You pass intermediate state. You branch based on results. The system only works because execution follows an order.
Frameworks like LangChain or LlamaIndex sit in the same role dbt plays for SQL. They do not make the logic smarter. They make the sequence visible. They define how outputs from one step feed the next, where retries happen, and how state moves through the system.

Without this layer, AI apps turn into glue code. Logic hides inside callbacks. Control flow leaks across files. Debugging becomes guesswork because there is no execution model to inspect. With orchestration, you regain lineage. You can point to a step and say what it did and why it ran.
For data engineers, this should feel natural. Orchestration exists to constrain complexity. The goal stays the same: make execution paths legible, failures local, and ownership clear. The tools change. The reason they exist does not.
Evaluation Is the Data Quality Layer
Evaluation exists to answer if the system can be trusted to behave the same way tomorrow. In data engineering, that question shows up as tests, checks, and expectations. In AI systems, it shows up as evals.
An eval runs the system against known inputs and inspects the outputs. Sometimes you compare against a reference answerm and sometimes you score for consistency, relevance, or format. The mechanics vary, but the role stays the same. You are checking whether the system drifts out of bounds.
In data engineering, you do not test because data might be wrong once. You test because it will be wrong eventually, and you want to catch it before someone else does. AI systems behave the same way. Outputs degrade quietly as inputs shift, context changes, or retrieval skews.
Without evals, AI apps stay in demo mode. They look convincing in isolation and fail under repetition. With evals, behavior becomes observable. You can track regressions, compare versions, and decide when a change actually improved the system.
Evaluation is governance. It is the layer that turns a clever pipeline into something you are willing to run every day.
Temperature Is Validation Variance
Temperature controls how much deviation the system allows in its output. Low temperature narrows the range of responses. High temperature expands it. The model explores more space instead of snapping to the most likely answer.
This is similar to variance tolerance. You are deciding how strictly the system must follow constraints versus how much freedom it gets to improvise. Tight variance produces repeatable output. Loose variance produces novelty.
The choice depends on where the output lands. If the result feeds another system, low variance protects downstream integrity. If the result faces a human, higher variance can add value. The decision is architectural, not stylistic.
For you as a data engineer, this reads like any other validation boundary. You pick how much drift is acceptable before the output stops being useful. Temperature simply exposes that choice instead of hiding it.
Final Thoughts
AI changed the build-versus-buy narrative across software. Teams no longer choose between purchasing tools and engineering everything from scratch. AI lets them assemble applications directly, or build AI-powered systems as part of existing platforms and that shift reshapes where leverage sits.
For you as a data engineer, knowing how these systems work is essential. AI applications depend on data flow, state, latency, and integrity. Those concerns already live in your domain. That puts you in a strong position to sit at the center of their success.
The future is now, don’t miss it out of pride.
Thanks for reading,
Yordan
PS: When things break, the people who build prompts call the people who build data.
PPS: Got a minute? Share how this publication helped you. Be a champion.